
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- shebang
- lambda
- 셔뱅
- has-a
- node.js
- down casting
- Java
- Stream
- pycharm
- extends
- 내부클래스
- 파이참
- identityHashCode
- dbeaver
- Wrapper class
- 얕은 복사
- 엔드포인트
- parameter group
- Up Casting
- singletone
- 깊은 복사
- generic programming
- arraycopy
- 스트림
- Inbound
- finalize
- public static final
- access modifier
- constructor
- 자바
- Today
- Total
٩(๑•̀o•́๑)و
20200308 - 컬렉션 프레임워크 본문
컬렉션 프레임워크
- 프로그램 구현에 필요한 자료구조와 알고리즘을 구현해 놓은 라이브러리
- java.util 패키지에 구현되어있음
- 개발에 소요되는 시간을 절약하고 최적화된 라이브러리를 사용할 수 있음
- Collection 인터페이스(딱 하나의 객체)와 Map 인터페이스(pair로 된 객체)로 구성됨
자료구조
- 배열 : 연속된 선형 자료구조. 논리적인구조=물리적인 구조. 중간에 데이터가 빠질 경우 땡겨와야하고 중간에 추가될 경우 뒤의 자료를 밀어야함 - 데이터를 넣고 빼는데 시간이 오래 걸림. 하지만 i번째 자료를 찾는데 굉장히 빠름(산술연산). fixed Length이기때문에 넘칠 경우 더 큰 배열을 생성후 카피해야함. 선형자료구조를 사용하되 조회가 빈번할 경우 사용. ==> JDK에 ArrayList , Vector. Vector는 jdk 2부터 존재했으며, 현재는 ArrayList를 자주사용(최적화가 잘 되어있음)
- linked list : 논리적으로는 다음 자료를 가리키지만 물리적으로는 떨어져있음. 논리적으론 선형, 물리적인 위치는 떨어져있음. 데이터의 추가 삭제가 용이. i 번째 자료를 찾는데 시간이 걸림(맨 처음부터 하나씩 찾아가야함). 동적 메모리가 허용되는 한 계속 연결하여 데이터 추가가 가능. 선형자료구조를 사용하되, 자료의 변동이 잦을 경우 사용
- Stack : Last In First Out - JDK에 Stack 사용. 혹은 ArrayList나 Vector로 직접 구현하여 사용하기도함. 맨 위를 Top이라 하며, push(), pop() 메서드 사용
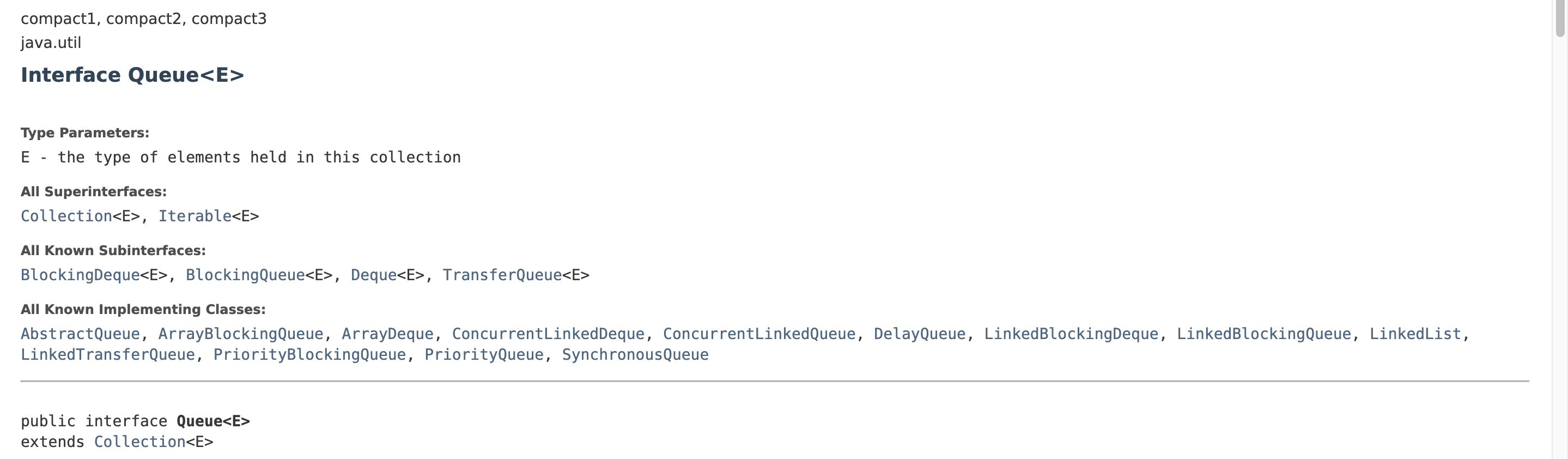
- Queue : First In First Out. 선입선출 - ArrayList로 구현하여 사용하는 것이 대부분. JDK에 PriorityQueue가 제공이 되고있으므로 사용하여도됨. 맨 앞을 front, 맨 뒤를 rear라고 하며, enqueue(), dequeue() 메서드 사용.
- Hash : 검색을 위한 자료구조. index = hash(key) . 해시함수에 key값을 넣으면 해시테이블의 어떤 위치에 넣으면 되는지/어느 위치인지 인덱스를 줌. 산술연산을 하기때문에 검색속도가 굉장히 빠르다. ( O(1) ) hash함수의 결과로 나온 값에 이미 데이터가 있을 경우에는 collision(충돌)이 발생했다고함. 가장 간단한 해시함수는 나머지연산. 해시테이블은 꽉 차게 사용하지 않는다. 약 75%가 차면 뻥튀기하여 사용. HashSet, HashMap 역시 내부적으로 해시구조.
- BTree : 부모 하위에 자식이 2개이하인 트리.
- BST (Binary Search Tree) : 검색을 위한 트리. 노드에 데이터가 들어가며, 데이터는 중복 허용하지 않음. 두번째 데이터부터는 비교를 한 후 넣는다. 노드보다 작을 경우 left side, 클 경우에는 right side로 넣는다. 노드하나를 기준으로 left side는 해당 노드보다 작은값들, right side는 큰 값들이 들어가게된다.




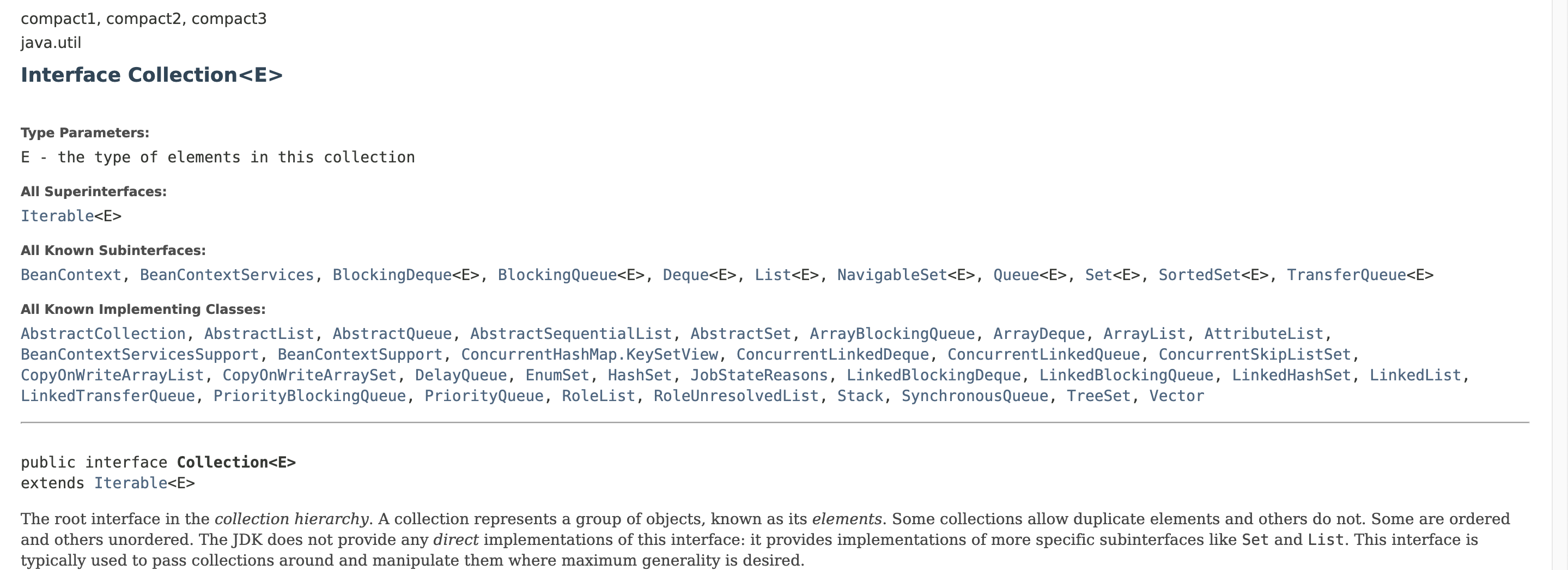
Collection 인터페이스
- 하나의 객체의 관리를 위해 선언된 인터페이스로 필요한 기본 메서드가 선언되어 있음
- 하위에 List, Set 인터페이스가 있음
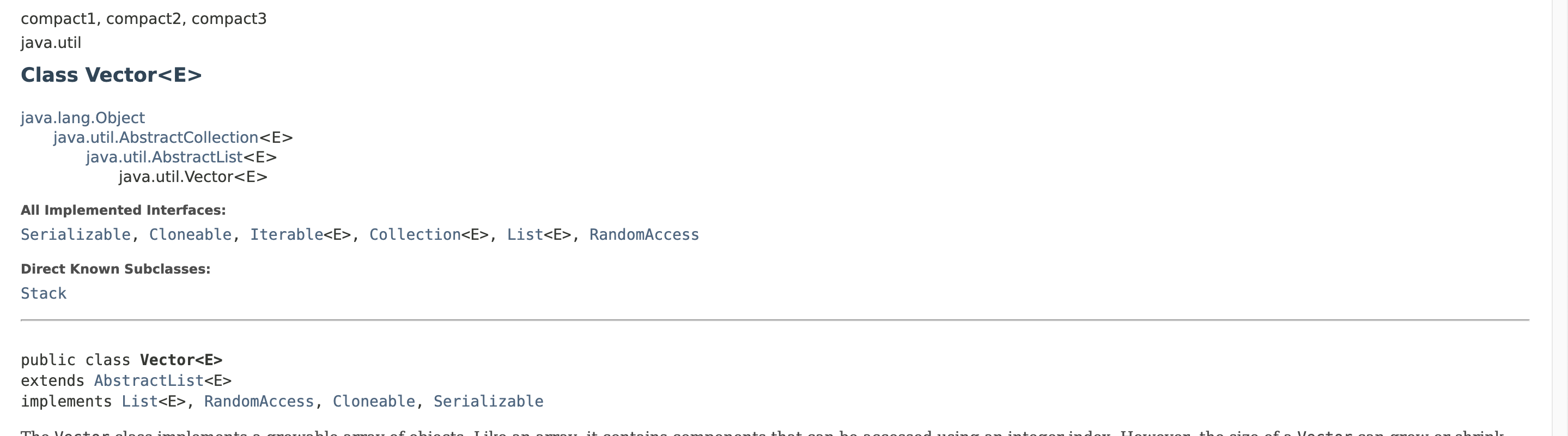
- List 인터페이스 : 순서가 있는 자료 관리. 중복 허용. 구현 클래스 - ArrayList, Vector, LinkedList, Stack
- Set 인터페이스 : 순서가 정해져있지 않음. 중복 허용하지 않음. 구현 클래스 - HashSet, TreeSet
- List는 순서가 있기때문에 get() 메서드 사용이 가능하다
- Set은 순서가 없기 때문에 get() 메서드 불가
- get()메서드는 List에만 존재!
Iterator 로 순회하기
- Collection의 개체를 순회하는 인터페이스
- 특히 Set인터페이스의 경우에는 순서대로 저장되지 않기때문에 몇번째꺼를 꺼냈다는 보장이 없음. 단순히 있는거를 꺼내는 방식 - 이때 사용하는게 Iterator 객체!
- 모든 Collection 객체의 경우 iterator()메서드를 호출할 경우 Iterator객체가 리턴되며, 이걸 가지고 순회를 할 수 있다.
- boolean hashNext() : 이후에 요소가 더 있는지를 체크하는 메서드이며, 요소가 있다면 true를 반환
- E next() : 다음에 잇는 요소를 반환.
Iterator ir = memberArrayList.iterator();


List 인터페이스
- Collection 하위 인터페이스
- 객체를 순서에 따라 저장하고 관리하는데 필요한 메서드가 선언된 인터페이스
- 배열의 기능을 구현하기 위한 메서드가 선언됨
- ArrayList, Vector, LinkedList
ArrayList vs Vector
- 객체 배열 클래스 - 내부적으로 배열로 되어있음.
- Vector는 java2부터 제공된 클래스
- 일반적으로 LinkedList를 더 많이 사용. 더 최적화된 라이브러리. 내부적으로는 Object array로 구현. 내부적으로 데이터 타입이 알아서 바뀐다. => generic타입으로 구현하여 사용!
- Vector는 멀티 쓰레드 프로그램에서 동기화를 지원. 모든 메서드에 synchronized 키워드가 들어가있음. 단일 쓰레드에서는 동기화가 오히려 오버헤드가 되기에 부적절함.
- 동기화(synchronization) : 두 개의 쓰레드가 동시에 하나의 리소스에 접근할때 순서를 맞추어서 데이터의 오류가 발생하지 않도록 함
- capacity와 size는 다른의미임 - capacity는 배열의 용량을 의미하며, size는 배열안에 몇개의 요소가 들어있는지를 의미.
- 처음 배열을 생성하면 10개짜리 배열이 생성됨(private static final int DEFAULT_CAPACITY=10;). 11번째 데이터가 들어올 경우 ArrayList는 뻥튀기를 시킨다 - 새로 메모리를 할당받아서 카피 진행. ==> capacity에 따라 증가하는것. 우리는 그냥 쭉 add하여 진행하면된다. (더 큰 메모리 할당&카피를 알아서진행)



ArrayList vs LinkedList
- 둘 다 자료의 순차적 구조를 구현한 클래스
- ArrayList는 배열을 구현한 클래스로 논리적 순서 = 물리적 순서 ==> i번째 요소 찾기가 굉장히 빠름 & 가장 많은 메서드를 가진 클래스 중 하나
- LinkedLIst는 논리적으로 순차적인 구조이지만, 물리적으로는 순차적이지 않을 수 있음. 요소 하나는 자료(data)+다음요소의 주소 로 구성 ==> 자료의 추가/삭제에 용이한 구조

Stack 구현하기
- Stack은 이미 Stack으로 제공됨.
- Last In First Out(LIFO) : 맨 마지막에 추가 된 요소가 가장 먼저 꺼내지는 자료구조
- ArrayList나 LinkedList로 구현할 수 있음
- 게임에서 무르기, 최근 자료 가져오기 등에 구현
- 맨 위를 Top으로 표시. push(), pop() 메서드 사용
- peek() 메서드 : pop()메서드와 다르게 remove를 하지 않음. 단순히 Top의 데이터를 보여주기만한다.

Queue 구현하기
- Firt In First Out(FIFO) : 먼저 저장된 자료가 먼저 꺼내지는 자료구조
- 선착순, 대기열 등을 구현할 때 가장 많이 사용되는 자료 구조
- ArrayList나 LinkedList로 구현할 수 있음
- 맨 앞을 front, 맨 뒤를 rear로 표시. enqueue(), dequeue() 메서드 사용
- Queue 인터페이스의 경우 여러 구현체가 존재. 필요할때 찾아서 써도 되지만 일반적으로는 ArrayList를 그냥 이용해서 큐를 많이 사용한다.

Set 인터페이스
- Collection 하위의 인터페이스
- 중복을 허용하지 않음
- List는 순서기반의 인터페이스이지만, Set은 순서가 없음
- get(i) 메서드가 제공되지 않음 (Iterator로 순회)
- 저장된 순서와 출력 순서는 다를 수 잇음
- 아이디, 주민번호, 사번 등 유일한 값이나 객체를 관리할 때 사용
- HashSet, TreeSet 클래스
- Set으로 관리할 객체가 논리적으로 같다라는 것에 대한 정의가 되어있는지를 체크해야함
- 정의가 되어있지 않는다면 재정의를 해줘야한다. (hashCode()와 equals()) - 특히, 사용자 정의 클래스의 경우 꼭 확인하기.

TreeSet 클래스
- 앞에 Tree가 붙음 - 객체의 정렬에 사용되는 클래스
- 중복을 허용하지 않으면서 오름차순이나 내림차순으로 객체를 정렬함 - 정렬의 조건을 구현해야함
- 내부적으로 이진검색트리(Binary Search Tree)로 구현되어있음
- 이진 검색 트리에 자료가 저장될 때 비교하여 저장될 위치를 정함
- 객체 비교를 위해 Comparable이나 Comparator 인터페이스를 구현해야함 - 정렬에 대한 메서드를 구현해야함
- String의 경우 Comparable 인터페이스를 구현한 상태(compareTo() 메서드)이기때문에 String으로 TreeSet을 사용할 경우 별도의 구현 없이 바로 정렬됨
Comparable 인터페이스와 Comparator 인터페이스
- 정렬 대상이 되는 클래스가 구현해야 하는 인터페이스
- implements Comparable<클래스> : compareTo(Object obj)메서드 구현. 매개 변수(obj)와 객체 자신(this)를 비교
- implements Comparator<클래스> : compare(Object this, Object obj)메서드 구현. 즉 두개의 매개변수 비교. & TreeSet생성자에 Comparator가 구현된 객체를 매개변수로 전달.
- 일반적으로 Comparable을 더 많이 사용.
- 이미 Comparable이 구현된 경우 Comparator를 이용하여 다른 정렬 방식을 정의할 수 있음.





Map 인터페이스
- 쌍으로 이루어진 객체를 관리하는데 필요한 여러 메서드가 선언되어있음
- Map을 사용하는 객체는 key-value 쌍(pair)으로 되어있고 key는 중복될 수 없음(유일해야함)
- 구현 인터페이스 - Hashtable , HashMap, TreeMap, Properties( extends Hashtable )
- key-value pair의 객체를 관리하는데 필요한 메서드가 정의됨
- key는 중복될 수 없음. (value는 상관없음)
- 검색을 위한 자료구조
- key를 이용하여 값을 저장하거나 검색, 삭제할 때 사용하면 편리함.
- 내부적으로 hash 방식으로 구현됨. index = hash(key). index는 저장위치
- key가 되는 객체는 객체의 유일성함의 여부를 알기위해 equals()와 hashCode()메서드를 재정의함 - Set과 비슷
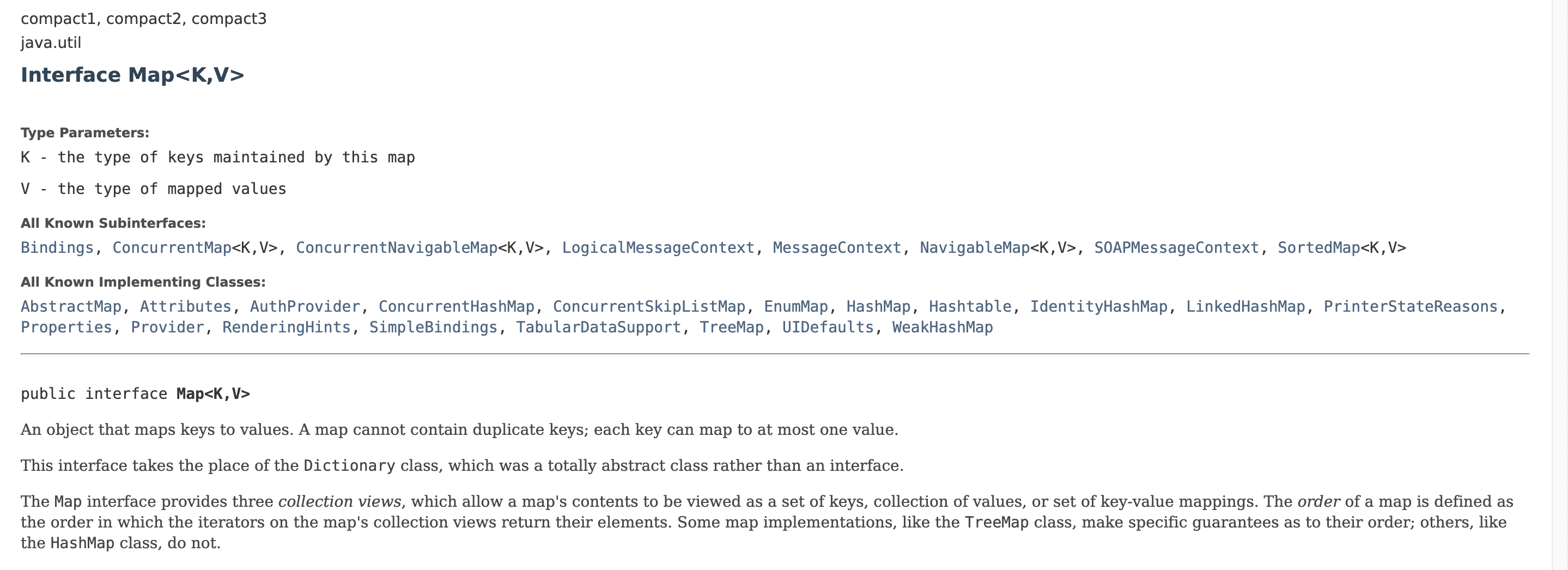
HashMap 클래스
- Map 인터페이스를 구현한 클래스 중 가장 일반적으로 사용하는 클래스
- HashTable 클래스는 java2부터 제공된 클래스로 Vector처럼 동기화를 제공함 - 지금은 HashMap을 일반적으로 사용
- pair 자료를 쉽고 빠르게 관리할 수 있음
- Collection과 달리 메서드가 많이 바뀜. 넣을땐 put()를 이용하여 pair로, 가져올땐 get()
- boolean containsKey(Object key) : returns true if this map contains a mapping for the specified key.
- boolean containsValue(Object value) : returns true if this map maps one or more keys to the specified value.
- void clear() : removes all of the mappings from this map
- V get(Object key) : returns the value to which the specified key is mapped, or null if this map contains no mapping for the key.
- V put(K key, V value) : Associates the specified value with the specified key in this map.
- V remove(Object key) : removes the mapping for the specified key from this map if present.
- boolean remove(Object key, Object value) : removes the entry for the specified key only if it is currently mapped to the specified value.
- Set<K> keySet() : returns a Set view of the keys contained in this map.
- Collection<V> values() : returns a Collection view of the values contained in this map.


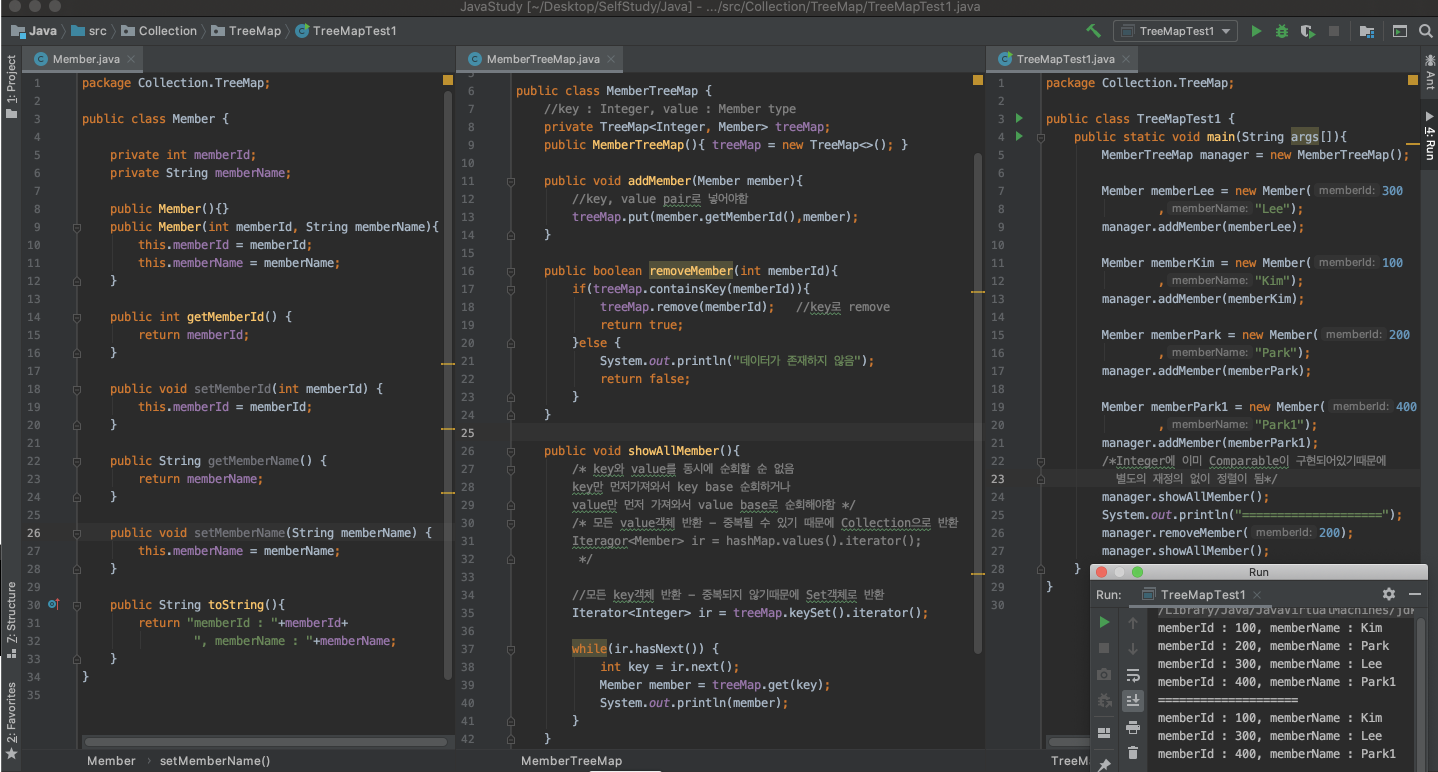
TreeMap 클래스
- Tree에 의해서 정렬이 되며, 그 기준은 key임
- key객체를 정렬하여 key-value를 pair로 관리하는 클래스
- key에 사용되는 클래스에 Comparable, Comparator 인터페이스를 구현
- java에 많은 클래스들은 이미 Comparable이 구현되어있음
- 구현된 클래스를 key로 사용하는 경우는 구현할 필요 없음. - 구현되지 않은 다른 클래스를 Key로 사용할 경우에는 Comparable을 구현해야함.

'Java' 카테고리의 다른 글
| 20200311 - 예외와 예외처리 (0) | 2020.03.11 |
|---|---|
| 20200309, 20200310 - 내부 클래스, 람다식, 스트림 (0) | 2020.03.11 |
| 20200308 - Generic 프로그래밍 (0) | 2020.03.08 |
| 20200308 - String, Wrapper Class (0) | 2020.03.08 |
| 20200307 - Object Class (0) | 2020.03.07 |



